
Python
画像処理技術(MediaPipe)を触ってみた
イブリン
更新日:2022/03/03
今回は、AR開発していく中で、OpenCVってどうやって使うの?画像認識技術MediaPipeを使ってどんなことができるの?
といったことを勉強しました。Pythonで簡単にできている画像認識技術についてご紹介します。
はじめに
1-1.学習するきっかけ
・AR開発をする中で、画像処理や画像認識などの機械学習を勉強する機会が増えた
・機会学習を手頃に試せるMediaPipeを試してみたい
・OpenCVの仕組みの理解とPythonを使って開発してみたかった
・今後BlenderでMediaPipeを使ってキャラクターを動かせるようにしていきたい
1-2.OpenCVとは?
OpenCV(Open Source Computer Vision Library)とは、
画像・動画に関する処理機能をまとめたオープンソースのライブラリです。
Intelが開発したライブラリで、OSSとして提供されているため、誰でも無料で使うことができます。
★画像の認識・編集(ノイズ除去・スケールなど)
★物体の検出
★AR・VR開発もできる
★ライブラリと組み合わせ可能(今回だとmediapipe)
詳細につきましては、OpenCVの公式サイトでご確認ください。
1-3.MediaPipeとは?
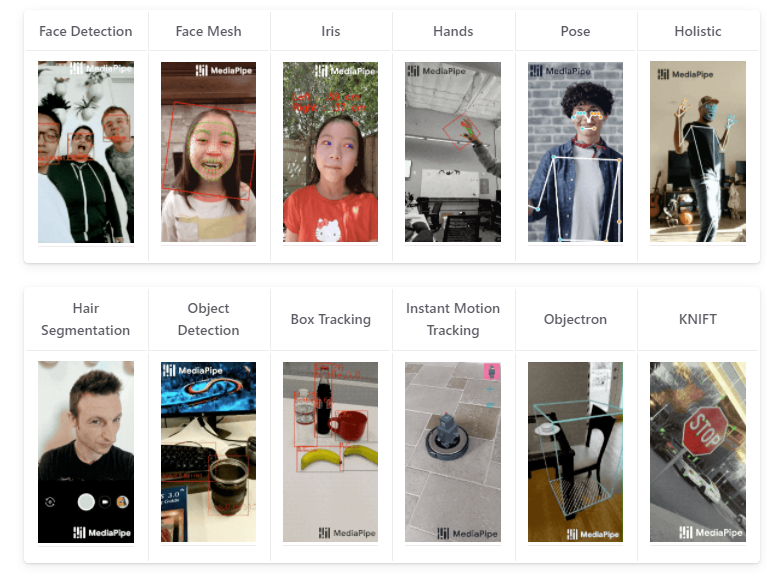
MediaPipeとは、
Google社が提供するライブストリーミングのためのオープンソースのMLソリューションです。
このMediaPipeを利用すると高性能なAI画像処理アルゴリズムを利用したARアプリケーション等を簡単に作成できます。
★クロスプラットフォーム(Andoroid,iOS,C++,JS,Python)でMLプラグインを構築
★CPU/GPUで動作可能
★機械学習技術による画像認識ソリューション
・顔認識(Face Detection)
・フェイスメッシュ(Face Mesh)
・手の検出(Hand Detection)
・姿勢推定(Pose)
・物体検出など
詳細につきましては、MediaPipeの公式サイトでご確認ください
動作環境
2-1.動作環境について
Anaconda
Pythonで使用されるライブラリプラットフォーム (https://www.anaconda.com/)
Anaconda Promptを開いて、「python」と入力して実行
続いて「print(‘Hello Python’)と入力してHello Pythonと出力されたら設定完了
Visual Studio Code(VSCode)
Microsoft社が開発している自由度と拡張性の高い「エディタ」
(https://azure.microsoft.com/ja-jp/products/visual-studio-code/)
MediaPipe
Google社が2019年より提供しているオープンソースで、動画などのストリーミングメディアに対して機械学習技術(ML)を使って推論することに特化したフレームワーク
(https://google.github.io/mediapipe/)
MediaPipeのインストール(pip install mediapipe)
MediaPipeのインポート(import mediapipe)
OpenCV
Intelが開発したオープンソースの画像処理ライブラリ(https://opencv.org)
サポートOS:-Windows -Mac -Linux -Andoroid -iOS
サポート言語:-C++ -Python -Java
豊富なコンテンツ(画像処理、機会学習、AR、VR)
【インストール】
※MediaPipe v.0.8.8以上をインストールすると、Python版OpenCVライブラリ(opencv_contrib_python)が一緒にインストールされる
→pip listで確認できる(もしなければ pip install open-contrib-pythonインストールを行う)
2-2.Anaconda&VSCodeの環境設定
1. Anaconda Navigatorを開いてEnviroments>createで仮想環境を作成します。
2. プロジェクト名を決めてpythonにチェックを入れて実行します。
3. 次にターミナル上で仮想環境が立ち上がるように設定します
4. 矢印ボタンをクリックしてopen Terminalを選択すると、自分で登録した仮想環境が立ち上がります
5. mediaPipeを学習する用のソフトを入れます(mkdir 新規ファイル名)
6. VSCodeでpythonインストール(Microsoft社が出しているもの)
7. 作業環境をCtrl+Shift+Pで検索Selectで検索して、1で作成したAnaconda環境を適応させます
8. conda info —envsで環境が適応されているか確認してください
9. pythonファイルにprint(‘Hello Python’)を入力して、ターミナルで実行出来たら完成!!
OpenCV
3-1.OpenCVで画像の読み込みと色変換

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
import cv2 img = cv2.imread('cat.jpg') #白黒画像 res1 = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #光の三原色(色相、彩度、明度)明るさなど res2 = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) #BGR(OpenCV)→RGBに変換 res3 = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) cv2.imwrite('res1.jpg', res1) cv2.imwrite('res2.jpg', res2) cv2.imwrite('res3.jpg', res3) |
3-2.OpenCVで動画の再生

|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import cv2 #webカメラの起動"0" cap = cv2.VideoCapture(0) #print(cap.isOpened()) #一コマごとに画像で表示 while cap.isOpened(): success,image = cap.read() if not success: break #動画だと左右反転に鳴るためflip関数を使用 image = cv2.flip(image,1) cv2.imshow('play movie', image) #動画を途中で止めるための条件分岐 if cv2.waitKey(5) & 0xFF == 27: break cap.release() cv2.destroyAllWindows() |
Mediapipeを触ってみた
4-1.静止画像から画像認識をしてみる

1.MediapipeとopenCVのインストールと手(Hands)の認識を行う
|
1 2 3 4 5 6 7 8 9 10 11 12 |
#openCVとMediaPipeをインポート import cv2 import mediapipe as mp #MediaPipeが提供しているhandsの値を読み込む mp_hands = mp.solutions.hands mp_drawing = mp.solutions.drawing_utils mesh_drawing_spec = mp_drawing.DrawingSpec(thickness=2, color=(0,255,0)) mark_drawing_spec = mp_drawing.DrawingSpec(thickness=3, circle_radius=3, color=(0,0,255)) #認識させる画像を読み込む img_path = 'hands.jpg' |
2.認識精度を設定
【ポイント1】handsの呼び出しをwith文にします。
with文にすることで、返しと終了を気にしなくても良いようにします。
【ポイント2】with文を呼び出す変数を定義する必要があります。
as以降で変数を定義
【ポイント3】検出精度について理解する必要があります。
検出精度は0~1の間で画像の検出精度を設定することができます。
0にすると検出精度が最も低く、1に近づきほど高くなります。
検出精度を低くすると画像にある手っぽいものが、認識されやすくなります。
一方で誤検出も増える。
逆に1に近づけていくと手として検出される範囲が厳しくジャッジされるため、
疑わしい場所は検出されなくなり、厳しくしすぎるとなにも検出されなくなる可能性もあります。
パラメーターは、常にトレードオフの関係にあることを抑える必要があります。
【ポイント4】手の数の上限値を設定
上限値を設定しないと1つの手しか認識されません。
今回使用する画像の手の数は4つなので4としています
【ポイント5】ランドマーク認識
ランドマークは、この画像でいう赤い丸●です。
この検出は、手の位置を追跡して自動で計算を行ってくれますが、
ランドマーク検出は、すべての入力画像を対象として実行されるため、情報量が多くなります。
そのため、基本的にはfalse,動画の場合も同様にfalse設定を行う必要があります。
|
1 2 3 4 5 6 7 8 |
#認識する手の数と認識精度を設定する with mp_hands.Hands( #手の数の上限 max_num_hands=4, #検出精度 min_detection_confidence=0.5, #ランドマーク検出 static_image_mode=True) as hands_detection: |
3.画像の編集を行う
画像のリサイズはopenCVの処理なので、詳しくはopenCVの公式サイトで確認してみてください。
最後に、検出された1つの画像のキーポイントを検出して、結果を出力します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
\#サイズの縮小処理(openCV) image = cv2.imread(img_path) image = cv2.resize(image, dsize=None, fx=0.3, fy=0.3) #色変換(BGR→RGB) rgb_image = cv2.cvtColor(image,cv2.COLOR_BGR2RGB) #リサイズ height = rgb_image.shape[0] width = rgb_image.shape[1] #顔検出の結果をresultsに results = hands_detection.process(rgb_image) #検出結果を別の画像名としてコピーして作成 annotated_image = image.copy() |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
for hand_landmarks in results.multi_hand_landmarks: #for id, lm in enumerate(hand_landmarks.landmark): # print(id, lm.x) mp_drawing.draw_landmarks( image = annotated_image, landmark_list = hand_landmarks, connections = mp_hands.HAND_CONNECTIONS, landmark_drawing_spec = mark_drawing_spec, connection_drawing_spec = mesh_drawing_spec ) cv2.imwrite('result3.jpg' , annotated_image) |
4-2.動画から画像認識をしてみる

1.動画を読み込む
import文と値の読み込みはhandsの書き方と同じです。今回はHolisticを使用していますので、変数名を変更する必要があります。
前のHandsでは画像を読み込んでいましたが、今回は読み込みたい動画を指定して動画を読み込みます。
|
1 |
cap_file = cv2.VideoCapture('movie2.mp4') |
|
1 2 3 4 5 |
while cap_file.isOpened(): success, image = cap_file.read() if not success: print("empty camera frame") break |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
mp_drawing.draw_landmarks( image=image, landmark_list=results.face_landmarks, connections=mp_holistic.FACEMESH_TESSELATION, landmark_drawing_spec=None, connection_drawing_spec=mesh_drawing_spec ) mp_drawing.draw_landmarks( image=image, landmark_list=results.pose_landmarks, connections=mp_holistic.POSE_CONNECTIONS, landmark_drawing_spec=mark_drawing_spec, connection_drawing_spec=mesh_drawing_spec ) mp_drawing.draw_landmarks( image=image, landmark_list=results.left_hand_landmarks, connections=mp_holistic.HAND_CONNECTIONS, landmark_drawing_spec=mark_drawing_spec, connection_drawing_spec=mesh_drawing_spec ) mp_drawing.draw_landmarks( image=image, landmark_list=results.right_hand_landmarks, connections=mp_holistic.HAND_CONNECTIONS, landmark_drawing_spec=mark_drawing_spec, connection_drawing_spec=mesh_drawing_spec ) cv2.imshow('holistic detection', image) |
|
1 2 3 4 |
if cv2.waitKey(5) & 0xFF == 27: break cap_file.release() |
4-3.Webカメラから顔認識してみる

1.カメラの認識
カメラの認識は、特別な処理を書き加える必要がありません。
VideoCaptureを0にするだけで、Webカメラから顔を認識することが可能です。
|
1 |
cap_file = cv2.VideoCapture(0) |
まとめ
今回の記事は、初心者でも気軽にMediaPipeを楽しんでもらえるような記事になったかとおもいます。
AR開発やBlenderの開発だけでなく、
OpenCVやPythonなどの学習などができ、充実した研究となりました。
発表会では、これ以外にPythonのWebUI(Streamlit)を使ったアプリも紹介しています。
【参考資料】