Python
Docker で OCR環境を構築(Tesseract + Python)
ヤス
公開日:2022/10/19
目次
はじめに
スマホで撮影した画像から数字を抽出する仕組みが必要だったので、Docker上にOCR環境を構築しました。
導入の簡単さと速度等から Tesseract + Python で構築しています。
OCR とは
OCRとは、Optical character recognition(光学文字認識)の略称です。
活字や手書きテキストの画像を文字コードの列に変換するソフトウェアです。
Tesseract とは
Google社が開発しているオープンソースの光学式文字認識ソフトウェアです。
無料で利用できるため、試しに使ってみるのに便利です。
Dockerfile を作成する
Python のライブラリである Pyocr がTesseractをOCRツールとして利用できるためDockerfile 作成時にインストールしています。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
FROM ubuntu:22.04 RUN apt-get update RUN apt-get upgrade -y RUN apt-get install -y software-properties-common RUN add-apt-repository ppa:alex-p/tesseract-ocr5 RUN apt-get update RUN apt-get install -y tesseract-ocr libtesseract-dev RUN apt-get update RUN apt-get install -y python3 python3-pip RUN apt-get clean RUN pip3 install pyocr RUN rm -rf /var/lib/apt/lists/* |
上記のDockerfile をビルドして、コンテナを作成します。
|
1 |
docker build -t tesseract:python-ocr ./Dockerfile |
数字のみ解析するpythonファイルを作成
コンテナ内にOCR解析用の場所を作成して、Python ファイルを作成します。
|
1 2 |
mkdir /var/ocr vi /var/ocr/ocr.py |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
#!/usr/bin/python3 from PIL import Image import sys import json import os import pyocr import pyocr.builders #OCRが利用可能か arr_ocr_tool = pyocr.get_available_tools() if len(arr_ocr_tool) == 0: print("No OCR tool found") sys.exit(1) ocr_tool = arr_ocr_tool[0] #OCR設定(数字と-.のみ認識) builder = pyocr.builders.TextBuilder(tesseract_layout=6) builder.tesseract_configs.append("digits") #OCR実行 ocr_txt = ocr_tool.image_to_string( Image.open("/var/ocr/digits.png"), lang="eng", builder=builder ) #実行結果をJSONで表示 arr_ocr = {} arr_ocr['digits'] = ocr_txt ocr_json = json.dumps(arr_ocr) print ("Content-type: application/json\n") print (ocr_json) |
実際に解析してみる
手書きの数字ファイル(digits.png)を作ってみて解析してみました。
解析ファイル
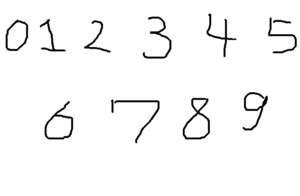
解析結果
コンテナ内で下記を実行。
|
1 |
python3/var/ocr/ocr.py |
・問題なく数字が読み取れました。
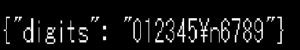
まとめ
Docker で OCR環境を構築する方法を説明させていただきました。
日本語の解析精度は高くないため、日本語を解析したい場合は学習を行って精度を高めていく必要がありそうです。